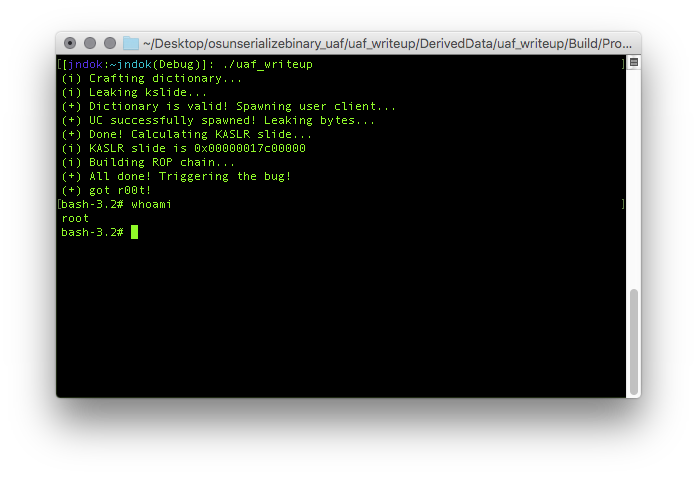
第一次运行运行example时总是出现 Module ‘AFNetworking’ not found 问题,查了好多关于Module的资料,对于问题的解决却没有帮助,后来偶然间在AFNetworking的github上的issues里找到解决办法,真是特别惭愧。应该点击文件夹内的AFNetworking.xcworkspace,而不是其他.xcodeproj文件。
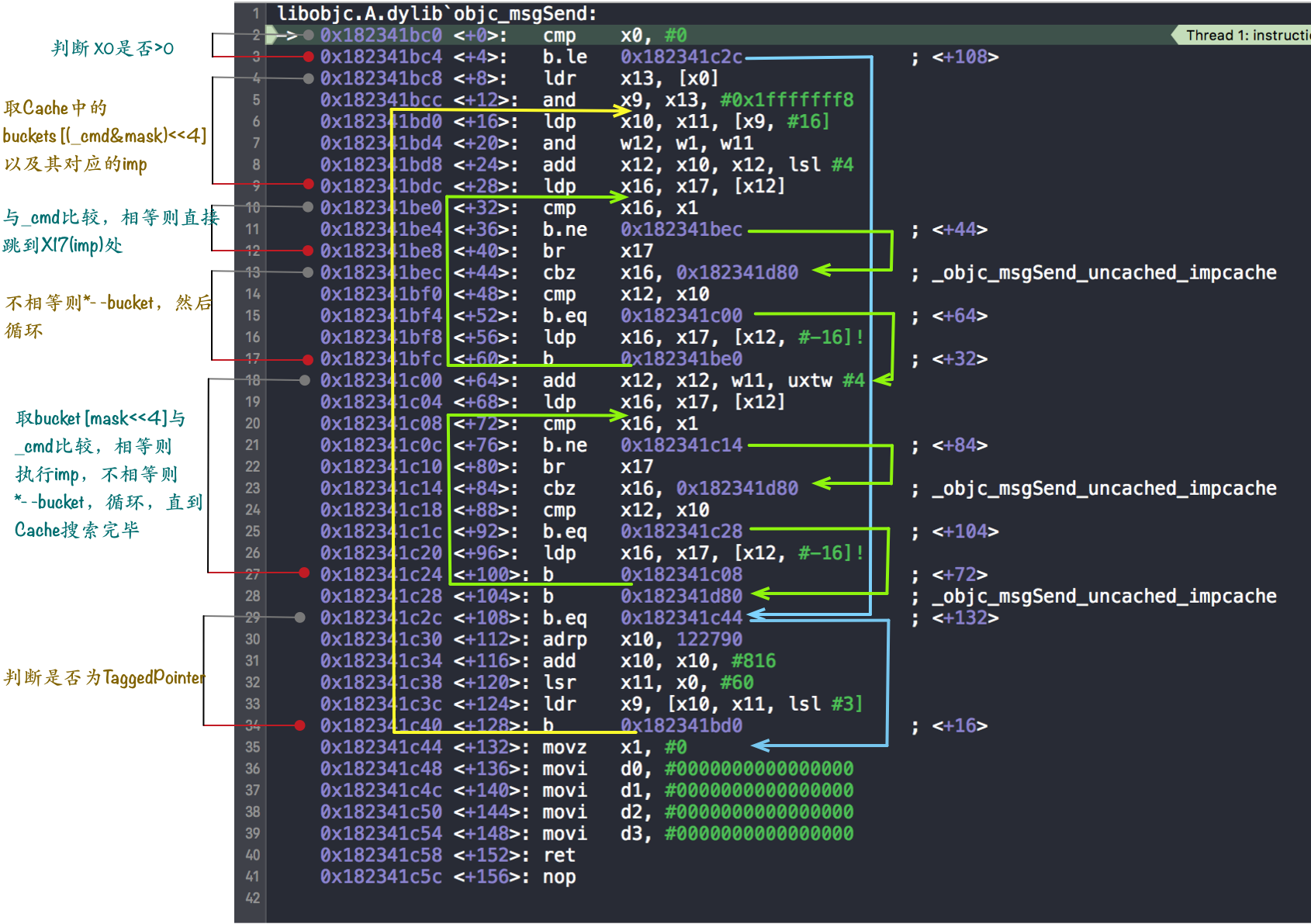
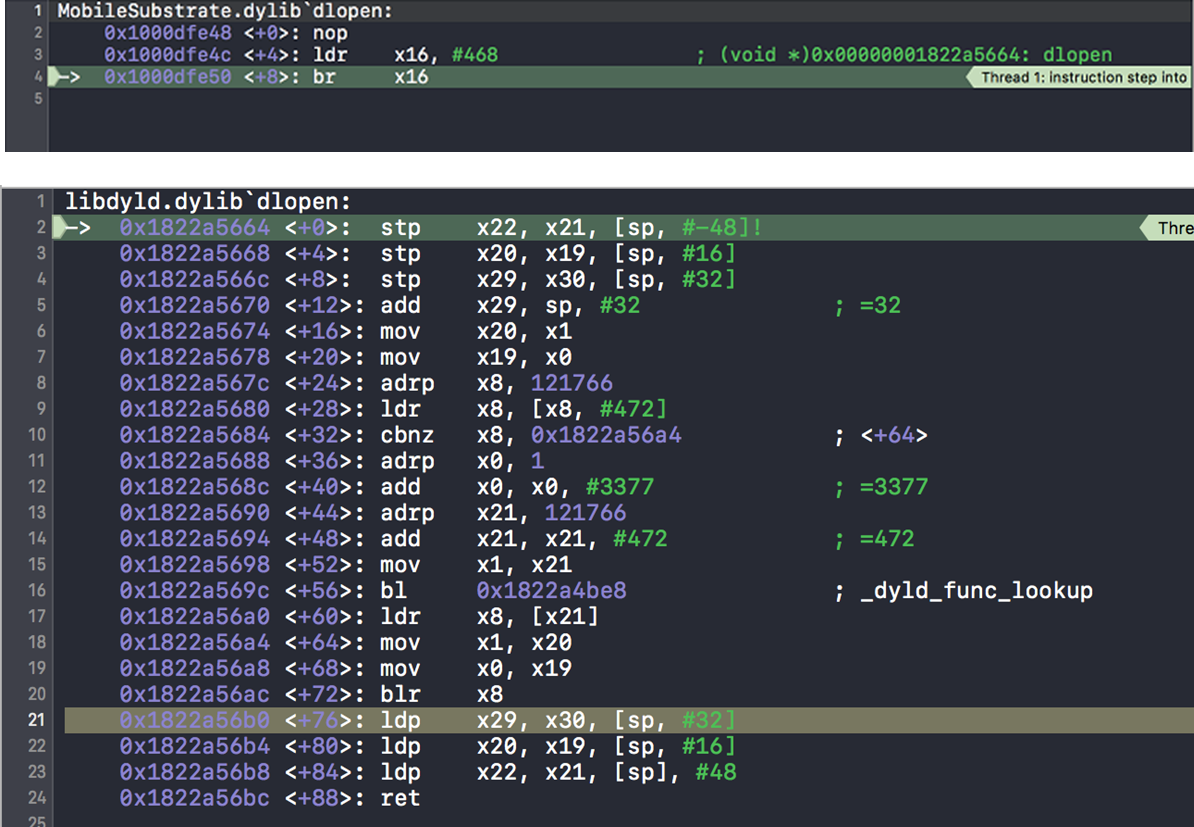
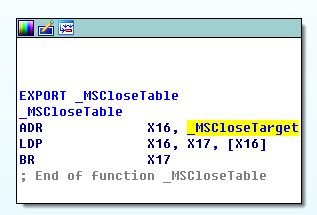
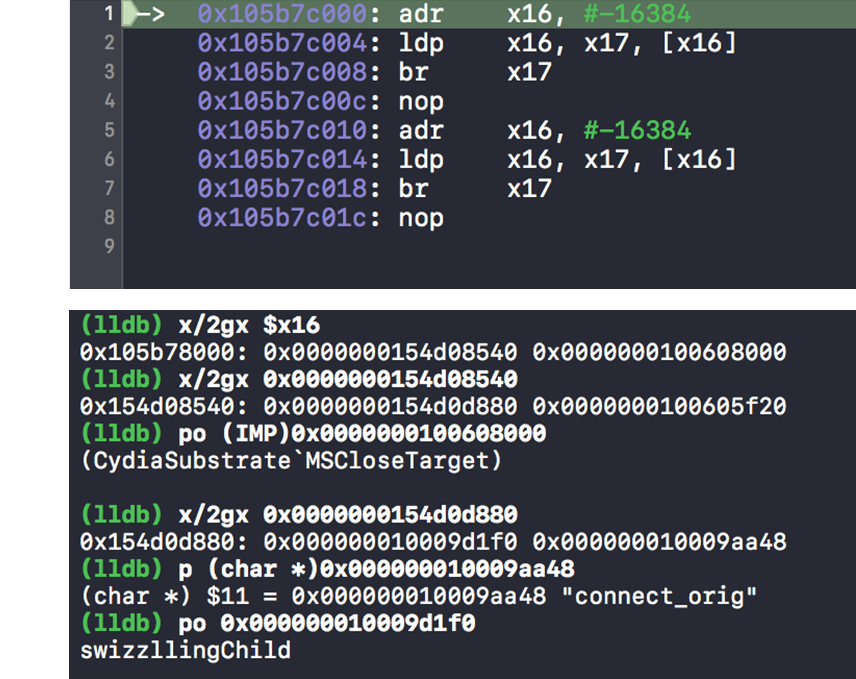
那么如何配置 trampoline 的数据呢?答案是通过 PC 相对寻址。PC(程序计数器)寄存器指示当前正在执行的指令的地址。我们将可写的数据页映射到可执行的代码页(trampoline page)旁边,然后使用 PC 相对寻址从相邻的可写数据页面加载 trampoline data,这样就达到了“可写”代码页的目的。
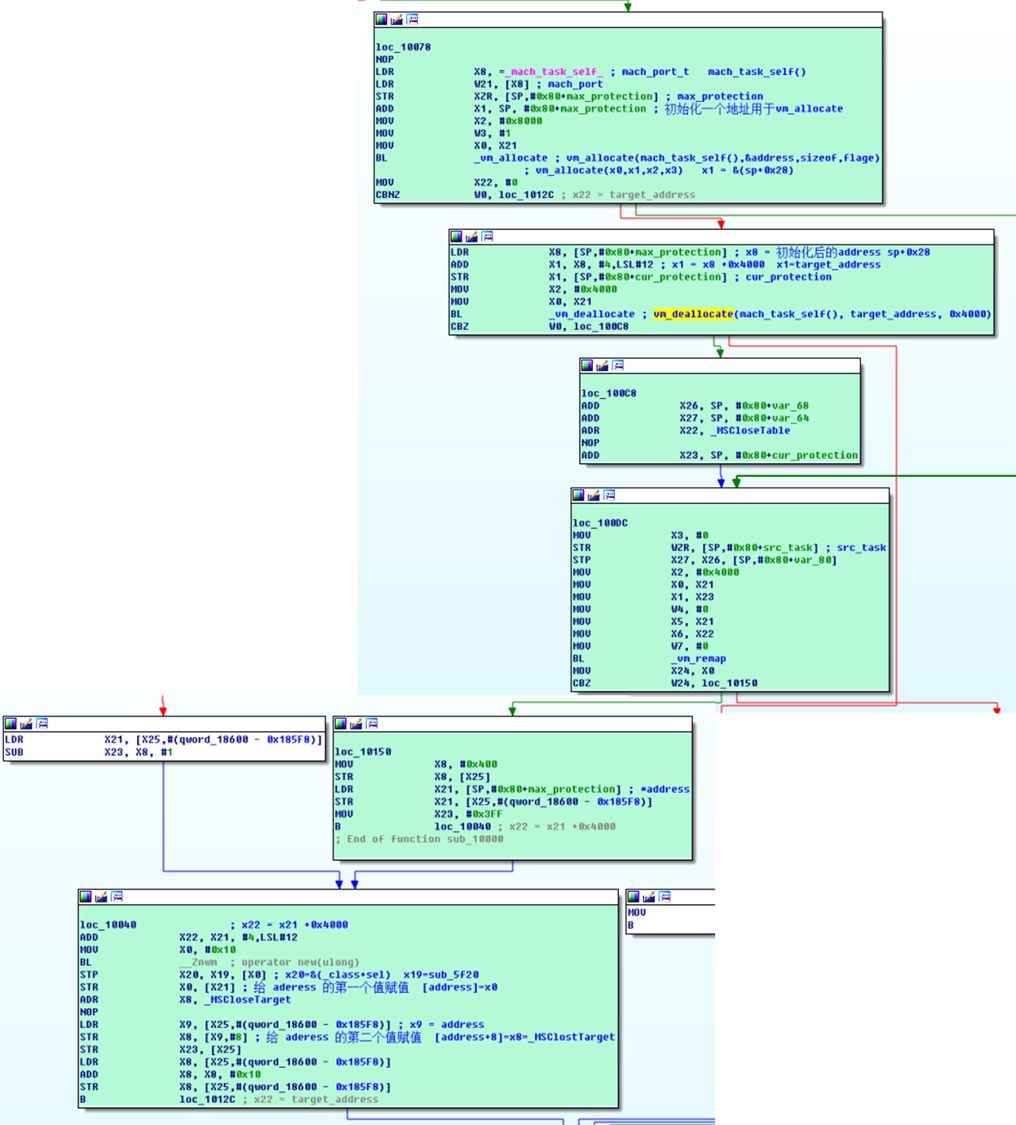
/* Try to allocate two pages */ kt = vm_allocate (mach_task_self (), &address, PAGE_SIZE*2, 1); if (kt != KERN_SUCCESS) { return ...; }
/* Now drop the second half of the allocation to make room for the trampoline table */ vm_address_t target_address = address+PAGE_SIZE; kt = vm_deallocate (mach_task_self (), target_address, PAGE_SIZE); if (kt != KERN_SUCCESS) { return0; }
/* Remap the trampoline table to directly follow the address page */ vm_prot_t cur_prot; vm_prot_t max_prot;
$ gdb ./a.out ...... Reading symbols from /home/scbox/Documents/a.out...(no debugging symbols found)...done. (gdb) b main Breakpoint 1 at 0x8048470 (gdb) r Starting program: /home/scbox/Documents/./a.out
Breakpoint 1, 0x08048470 in main () Missing separate debuginfos, use: debuginfo-install glibc-2.17-307.el7.1.i686 (gdb) p system #打印system()函数的地址 $1 = {<text variable, no debug info>} 0xf7e36f70 <system> (gdb) p exit#打印exit()函数的地址 $2 = {<text variable, no debug info>} 0xf7e2a7a0 <exit> (gdb) info proc mappings process97414 Mapped address spaces:
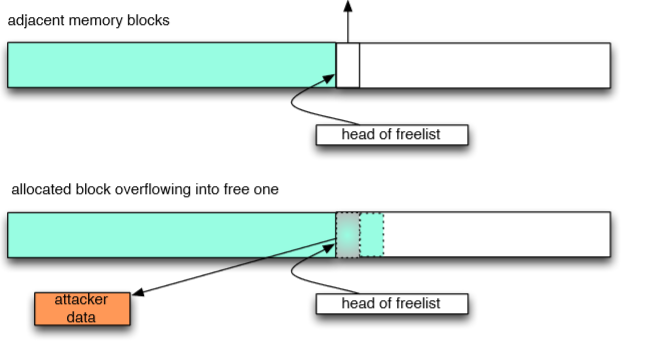
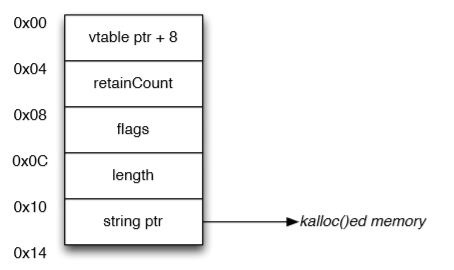
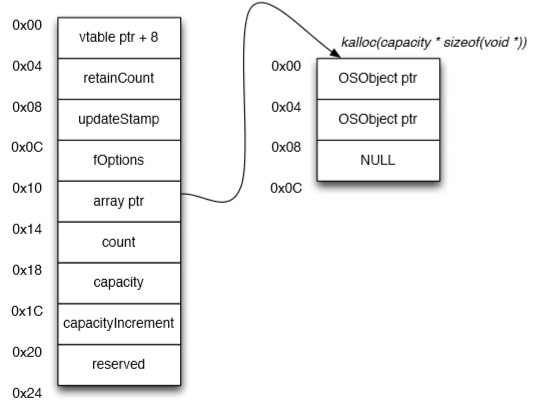
在这个例子中,可以看到键值 CCCC 被设定了两次。第一次是插入到字典中,第二次更新键值的数值,且前一个值已被破坏。这个数据对象的破坏将会释放该数值对象本身,以及释放由 base64 编码重复的 Z 字符所组成的数值。我们也因此在内存中有效地戳了一个洞。拼图的最后一块是你构建的用于控制堆的 XML.plist 文件是没有问题的。
总结
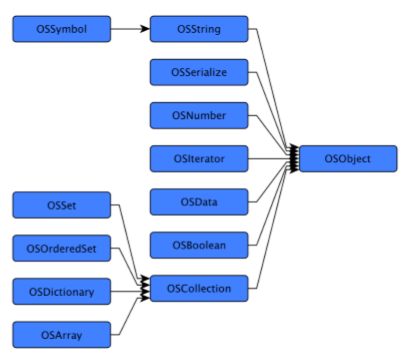
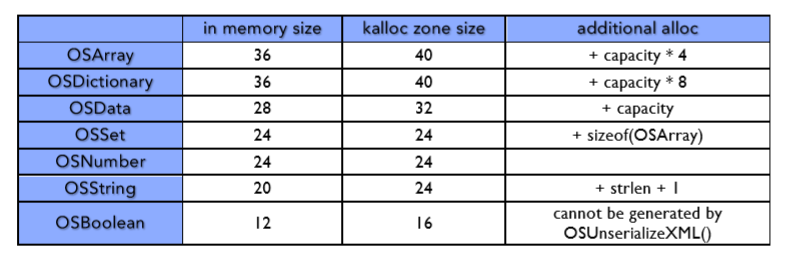
本文中我们首先重演了 iOS 内核堆空间分配,以及不同作者在之前所提到的它的利用。接着,我们介绍了其他的内核堆分配器以及它们所带来的额外的堆元数据。我们讨论了如何重写这些可以被利用的数据,以及提到了这些分配器目前的变化。接下来我们离内核堆元数据结构的利用只有一步之遥,我们讨论了 iOS C++ 内核对象,以及他们在内存结构的布局和在内存中重写他们可以得到什么。最后,我们介绍一种通用的技术,利用 OSUnserializeXML() 可以实现堆喷射和堆风水。这种新技术不仅可以使用任意数据喷射堆来完全控制它的布局,也可以使用有意思的内核应用数据来填充内核堆,该应用数据采用内核级别的 C++ 对象形式,一旦重写,将会允许任意代码执行。
References
[1] E. PERLA, M. OLDANI, ”A GUIDE TO KERNEL EXPLOITATION - ATTACKING THE CORE”, 2010, HTTP://WWW.ATTACKINGTHECORE.COM/ [2] S. ESSER, ”IOS KERNEL EXPLOITATION, BLACKHAT USA”, 2011 HTTPS://MEDIA.BLACKHAT.COM/BH-US- 11/ESSER/BH_US_11_ESSER_EXPLOITING_THE_IOS_KERNEL_WP.PDF [3] C. MILLER, D. BLAZAKIS, D. DAIZOVI, S. ESSER, V. IOZZO, R.-P. WEINMANN, ”IOS HACKER’S HANDBOOK”, 2012, HTTP://EU.WILEY.COM/WILEYCDA/WILEYTITLE/PRODUCTCD-1118204123,DESCCD- DESCRIPTION.HTML [4] A. SOTIROV, ”HEAP FENG SHUI IN JAVASCRIPT, BLACKHAT EUROPE”, 2007 HTTPS://WWW.BLACKHAT.COM/PRESENTATIONS/BH-USA-07/SOTIROV/WHITEPAPER/BH- USA-07-SOTIROV-WP.PDF
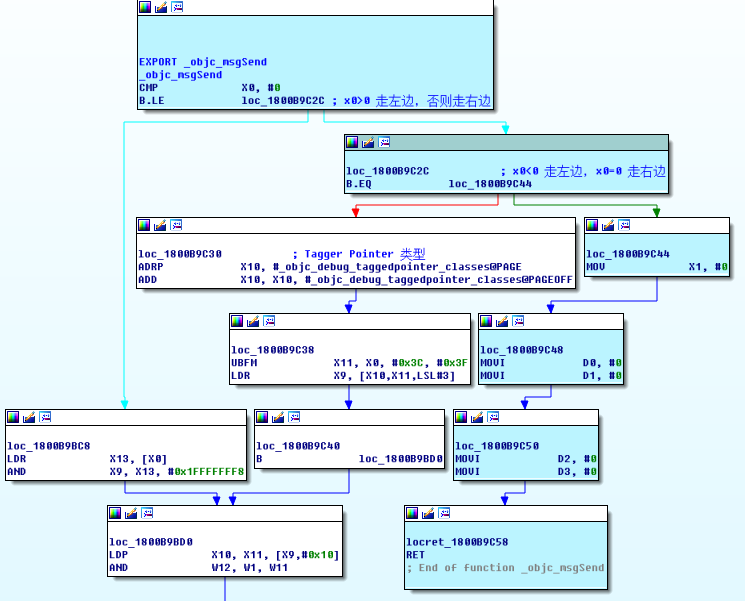
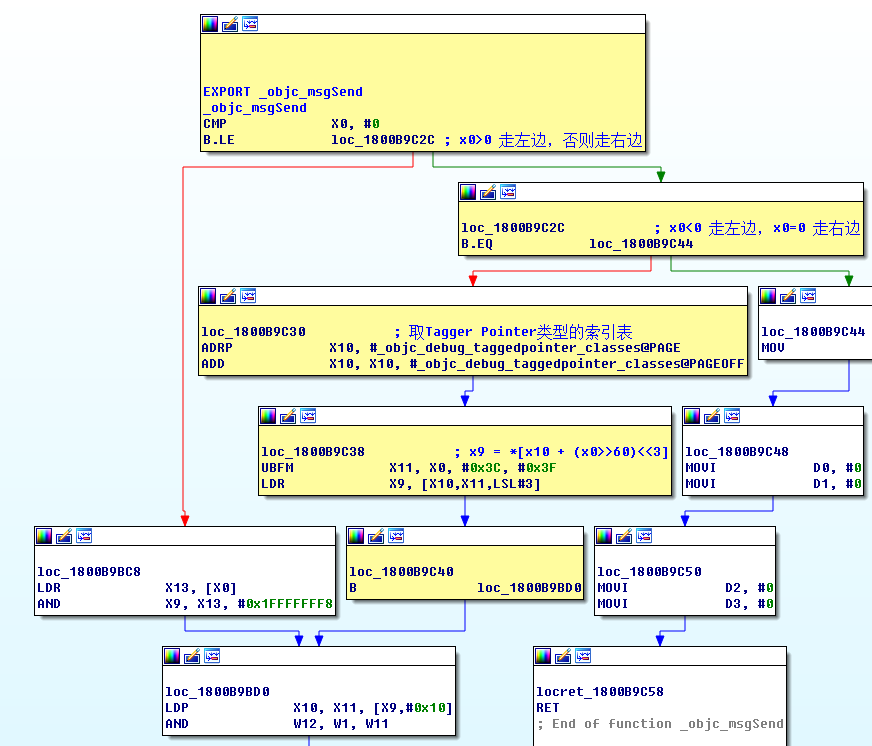
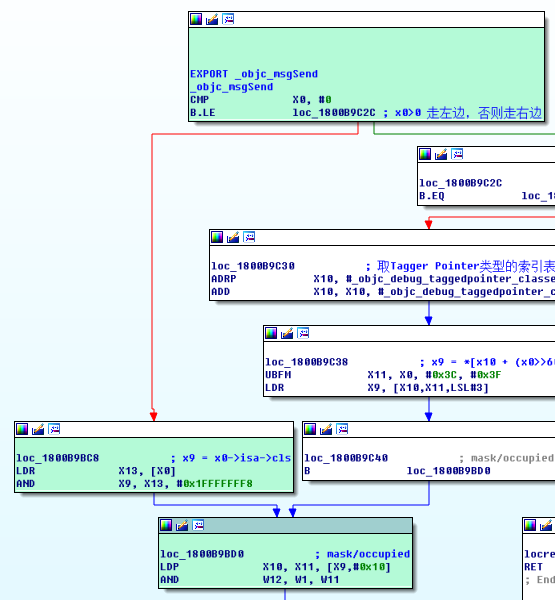
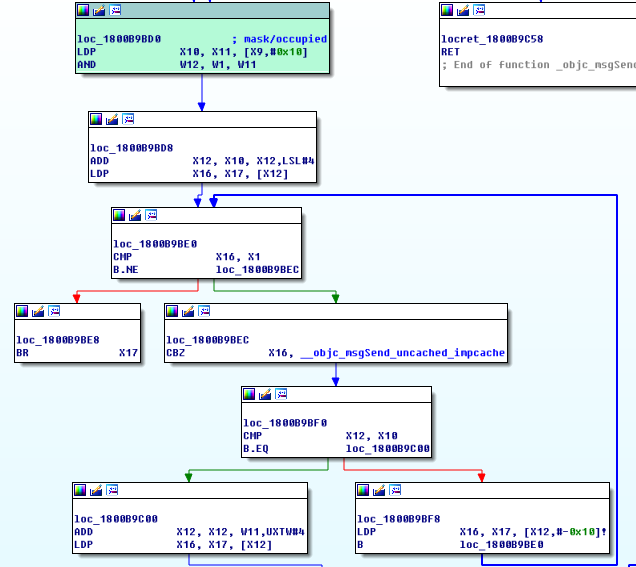
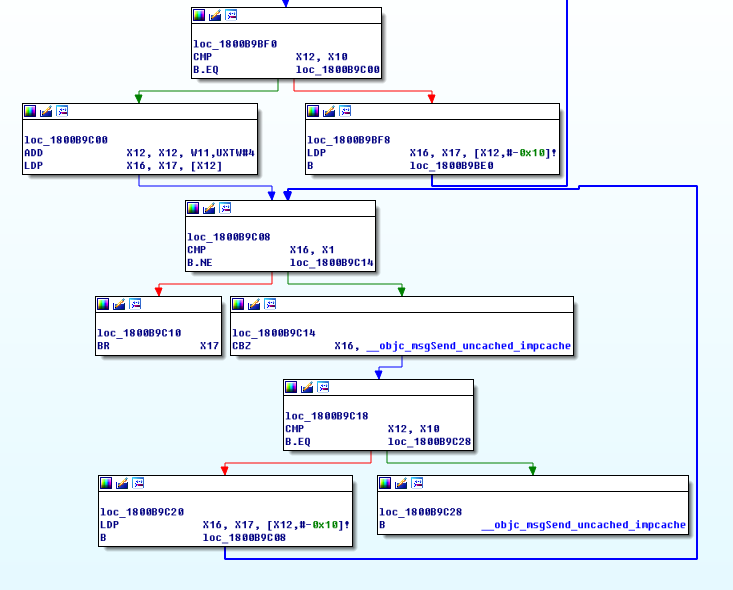
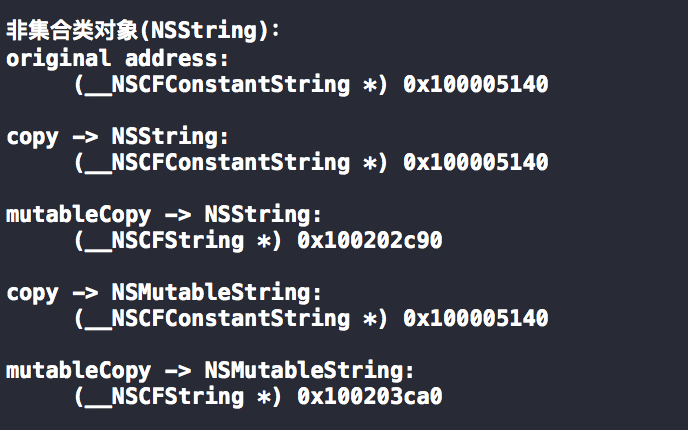
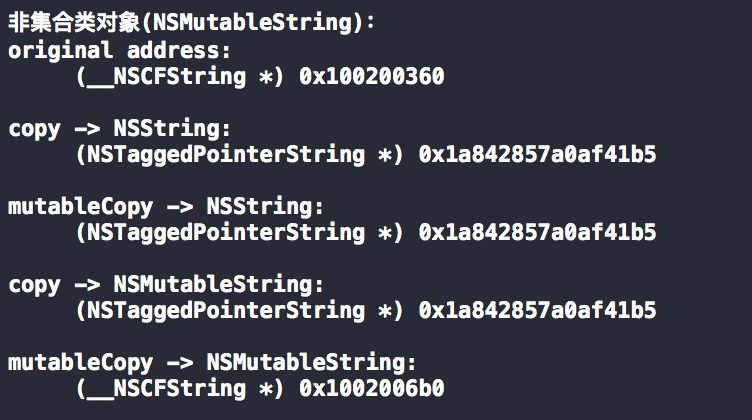
Tagged Pointer 是一个能够提升性能、节省内存的有趣的技术。我们知道,程序都使用了指针地址对齐概念。指针地址对齐就是指在分配堆中的内存时往往采用偶数倍或以2为指数倍的内存地址作为地址边界。几乎所有系统架构,包括 Mac OS 和 iOS,都使用了地址对齐概念对象。对于 iOS 和 MAC 来说,指针地址是以16个字节(或16的倍数)为对齐边界的,进一步说,分配的内存地址最后4位永远都是0。
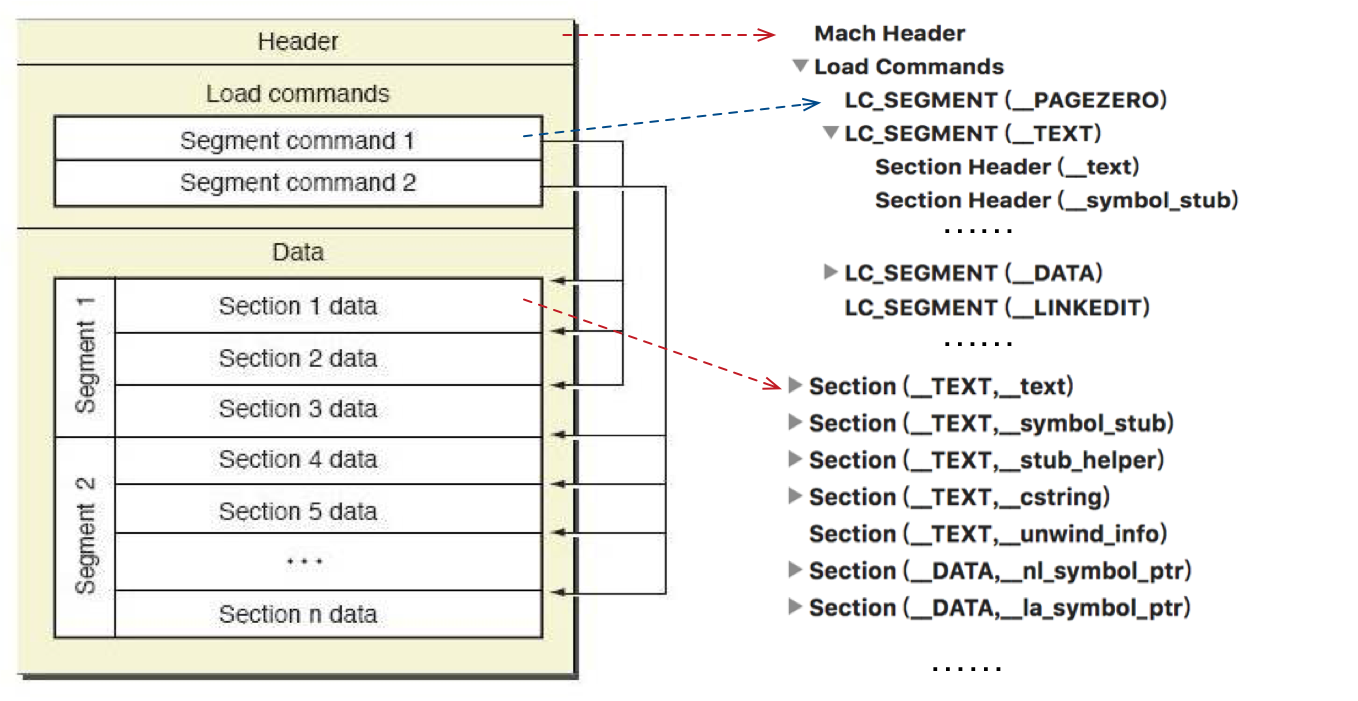
Mach-O 是 Apple 系统上(包括 MacOS 以及 iOS)的可执行文件格式,类似于 windows 上的 PE 文件以及 linux 上的 ELF 文件。上图左边为官方图,右边为用 MachOView 软件打开的 Mach-O 文件图。可以非常清晰的看到,这种文件格式由文件头(Header)、加载命令(Load Commands)以及具体数据(Segment&Section)组成。下面一一介绍。
Header
/*
* The 32-bit mach header appears at the very beginning of the object file for
* 32-bit architectures.
*/
struct mach_header {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
};
/* Constant for the magic field of the mach_header (32-bit architectures) */
#define MH_MAGIC 0xfeedface /* the mach magic number */
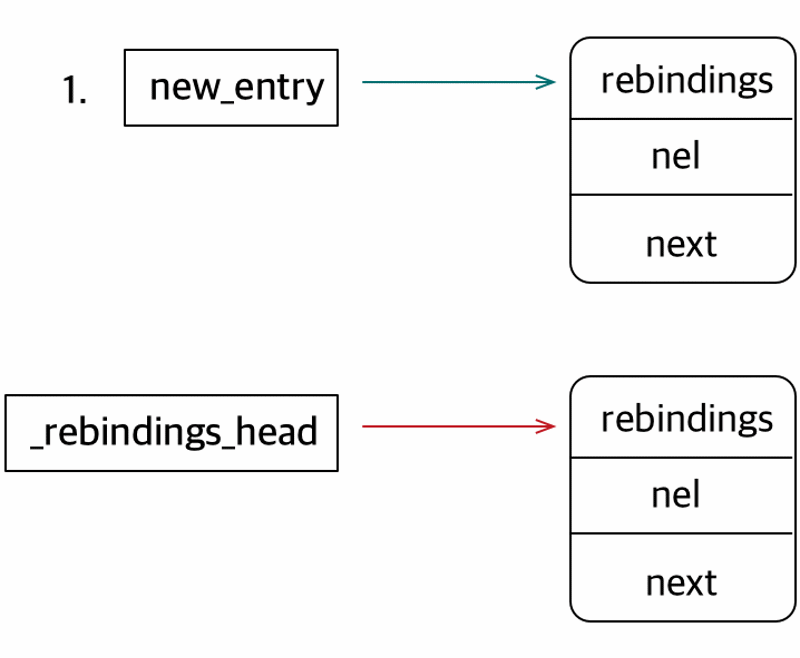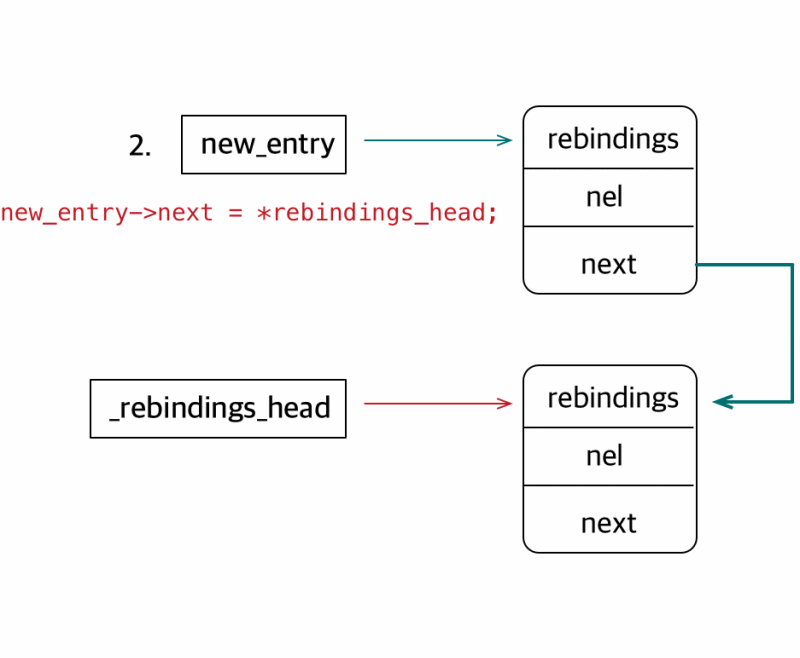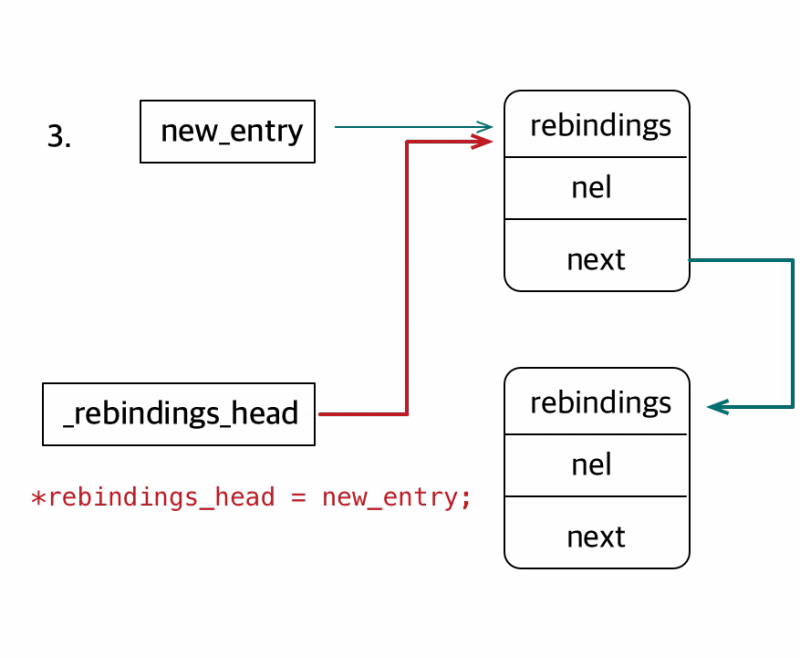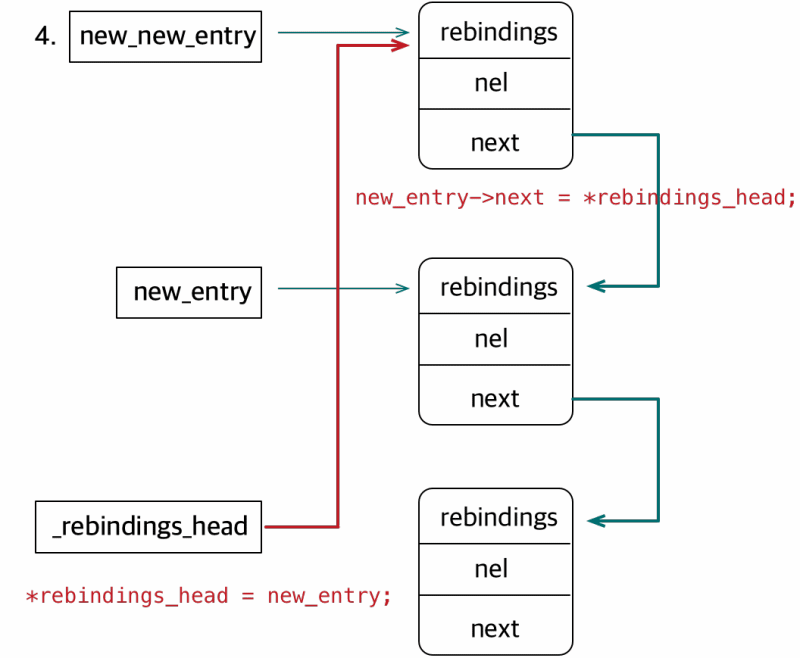
staticstructrebindings_entry *_rebindings_head; ...... intrebind_symbols(struct rebinding rebindings[], size_t rebindings_nel){ int retval = prepend_rebindings(&_rebindings_head, rebindings, rebindings_nel); if (retval < 0) { return retval; } // If this was the first call, register callback for image additions (which is also invoked for // existing images, otherwise, just run on existing images if (!_rebindings_head->next) { _dyld_register_func_for_add_image(_rebind_symbols_for_image); } else { uint32_t c = _dyld_image_count(); for (uint32_t i = 0; i < c; i++) { _rebind_symbols_for_image(_dyld_get_image_header(i), _dyld_get_image_vmaddr_slide(i)); } } return retval; }
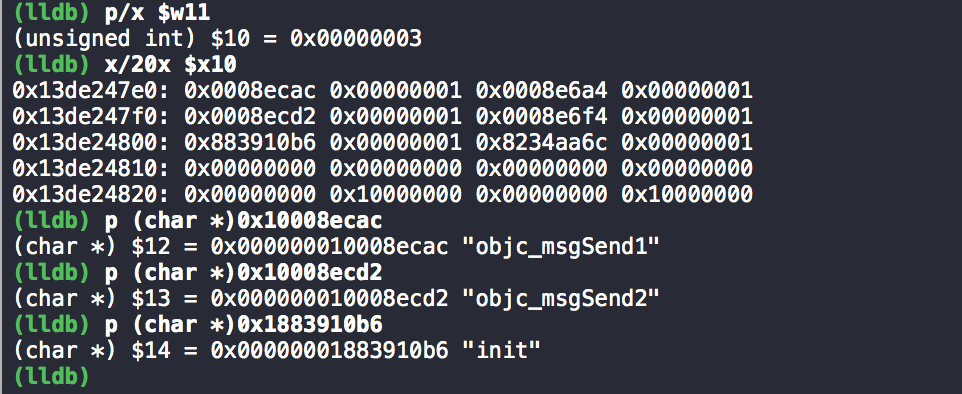
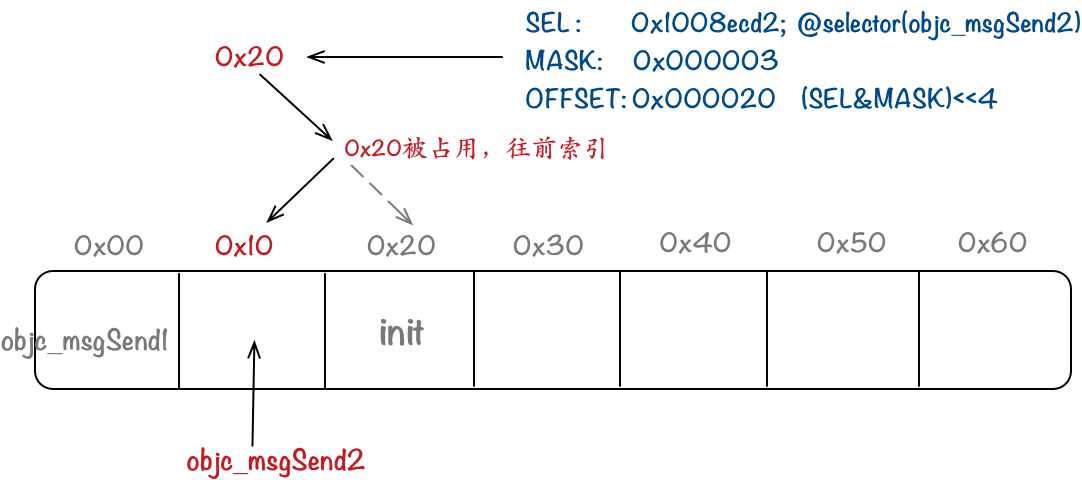
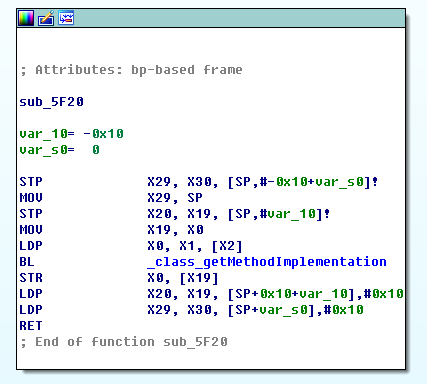
初始化一些值。字符指针 type 赋值为 method 的参数类型等描述。direct 赋值为 false,这个值代表着传入的参数 sel 是否为传入的参数 _class 中的方法,即是否为本类的方法。在接下来的第一个 for 循环中改变 direct 的值,这个循环就是用来判断 sel 是否是 _class 中的方法。如果不是本类的方法,执行第3步。如果是本类的方法,就跳过 if 函数,执行第4步。
如果不是本类的方法,就根据运行设备的架构(32位的arm,i386 和 x86_64)添加 class_getMethodImplementation(super,sel) 以及 执行 sel 对应的函数实现 的机器码,将返回值存储在 old 中。然后执行第5步。
如果是本类的方法,就跳过 if 函数,将找到的 sel 对应的方法 method 的实现 imp 赋给 old。然后执行第5步。
然后将 old 的值赋给 *result,即 oldConnect 函数指针。
如果 prefix != NULL,就给 _class 类添加一个 sel 为 prefix+sel,imp 为 old 的方法。
如果是本类的方法,执行第8步。如果不是,执行 else 分支,第9步。
direct = true,就通过 method_setImplementation 函数将传入的 newConnect 的函数地址赋给 sel 对应的方法 method 中的实现。即调用 connect_orig,会跳到 newConnect 的入口函数处。
direct = false,则通过 class_addMethod 函数将函数名为 sel,函数地址为 newConnect 函数地址,函数类型为 type 的方法添加到 _class 类中。
下面对主要部分作详细解释。
MSFindMethod
MSFindMethod 函数主要是用于找到传入的参数 sel 对应的 method。
static Method MSFindMethod(Class _class, SEL sel){ for (; _class != nil; _class = class_getSuperclass(_class)) { unsignedintsize; Method *methods(class_copyMethodList(_class, &size)); if (methods == NULL) continue;
for (unsignedint j(0); j != size; ++j) { Method method(methods[j]); if (!sel_isEqual(method_getName(methods[j]), sel)) continue;
free(methods); return method; }
free(methods); }
return nil; }
主要是通过两个 for 循环,遍历参数 _class 及其父类(父类的父类…直到基类),通过函数 class_copyMethodList 取得 _class 的方法列表,通过第二个 for 循环来遍历方法列表,与 sel 字符串作比较,如果匹配成功,即找到 sel 对应的方法,返回该 method,否则一直遍历,直到最后返回 nil。
这份源代码中,作者在使用 C++ 语言的初始化时,多用括号。如 int j = 0; 作者常使用 int j(0);
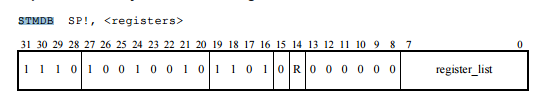
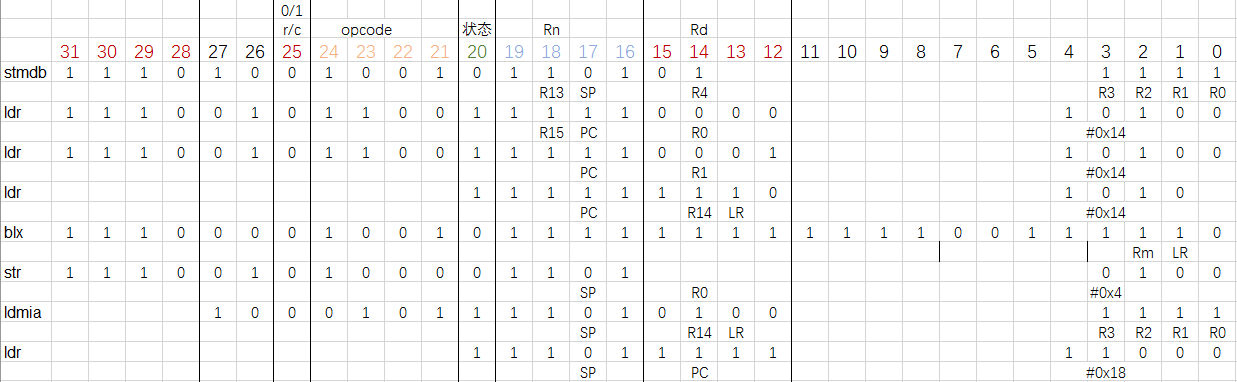
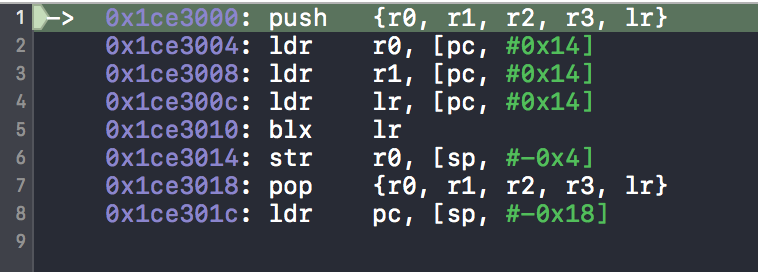
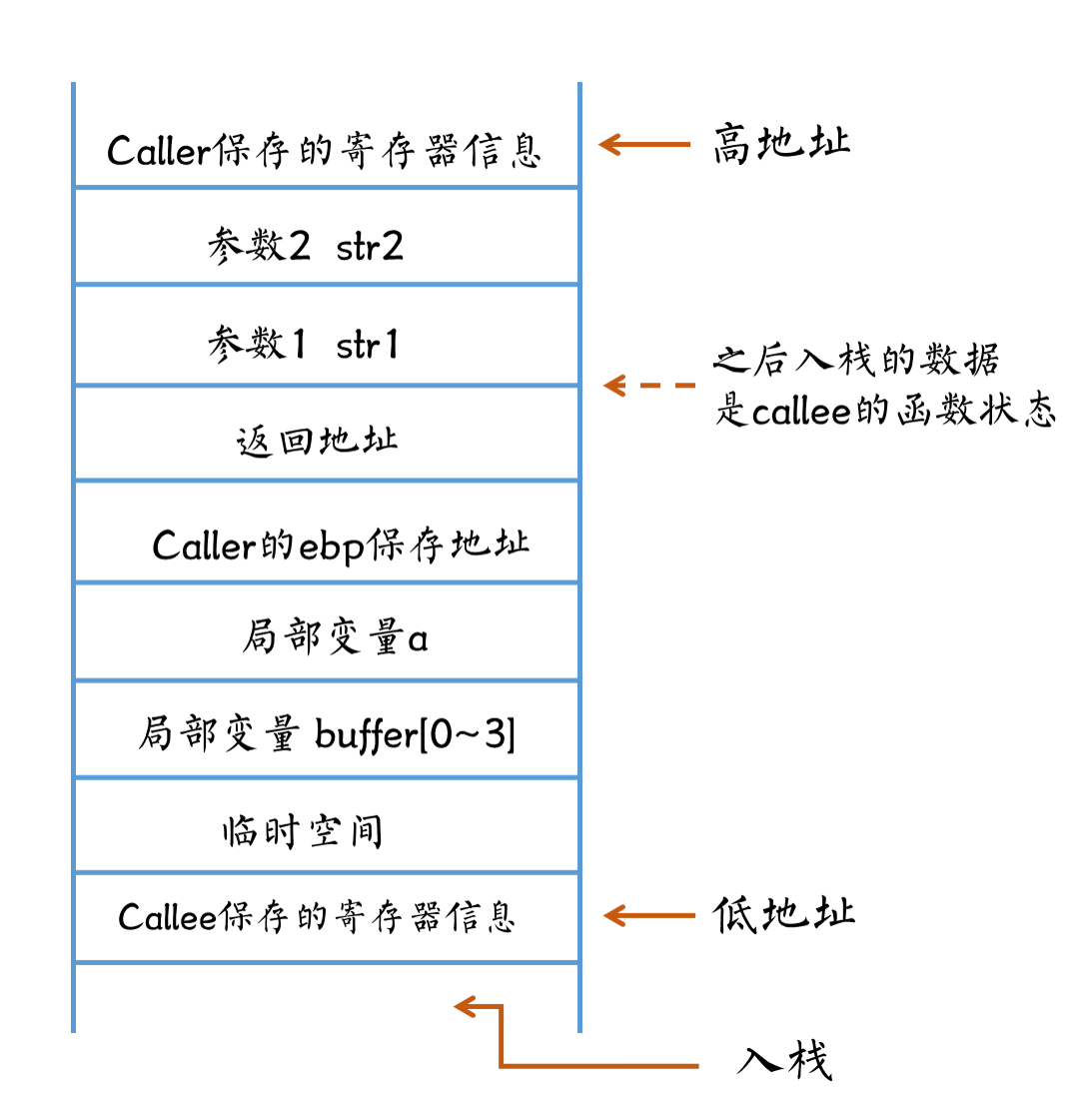
有关 pc 的计算。 PC 值(program counter)表示下一条指令存储的地址。由于 ARM 采用流水线来提高 CPU 利用效率,无论是 ARM7 的3级流水线还是 ARM9 的5级流水线,如果当前指令在执行,那么下一条指令一定正在译码,再下一条指令正在读取。 因此 PC 值实际上指的是当前执行指令的下一条的再一下条指令。
第5行,跳到 lr 寄存器中的地址处,执行指令代码,即 buffer[10],class_getMethodImplementation 函数,它的参数为 r0,r1。那么,也就是执行 class_getMethodImplementation(super, sel);
However, while these APIs function quite well when there are only a small number of people making modifications, they fail to satisfy more complex use cases; in particular, there are ordering problems if multiple people attempt to hook the same message at different points in an inheritance hierarchy.
Finally, it is important that classes that are being instrumented are not “initialized” as they are being modified (which would both change the ordering of the target program, as well as make it impossible to hook the initialization sequence); over time, the way Objective-C runtime APIs implement this has changed.
Substrate solves all of these problems by providing a replacement API that takes all of these issues into account, always making certain that the classes are not initialized and that the right “next implementation” is used while walking back up an inheritance hierarchy.
// extra_rc must be the MSB-most field (so it matches carry/overflow flags) // nonpointer must be the LSB (fixme or get rid of it) // shiftcls must occupy the same bits that a real class pointer would // bits + RC_ONE is equivalent to extra_rc + 1 // RC_HALF is the high bit of extra_rc (i.e. half of its range)
// future expansion: // uintptr_t fast_rr : 1; // no r/r overrides // uintptr_t lock : 2; // lock for atomic property, @synch // uintptr_t extraBytes : 1; // allocated with extra bytes
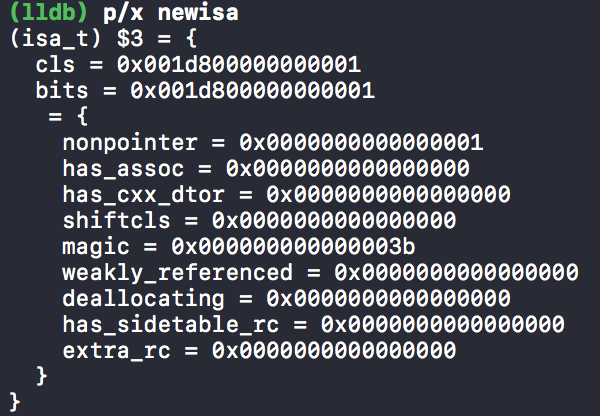
#if SUPPORT_INDEXED_ISA assert(cls->classArrayIndex() > 0); newisa.bits = ISA_INDEX_MAGIC_VALUE; // isa.magic is part of ISA_MAGIC_VALUE // isa.nonpointer is part of ISA_MAGIC_VALUE newisa.has_cxx_dtor = hasCxxDtor; newisa.indexcls = (uintptr_t)cls->classArrayIndex(); #else newisa.bits = ISA_MAGIC_VALUE; // isa.magic is part of ISA_MAGIC_VALUE // isa.nonpointer is part of ISA_MAGIC_VALUE newisa.has_cxx_dtor = hasCxxDtor; newisa.shiftcls = (uintptr_t)cls >> 3; #endif
// This write must be performed in a single store in some cases // (for example when realizing a class because other threads // may simultaneously try to use the class). // fixme use atomics here to guarantee single-store and to // guarantee memory order w.r.t. the class index table // ...but not too atomic because we don't want to hurt instantiation isa = newisa; } }
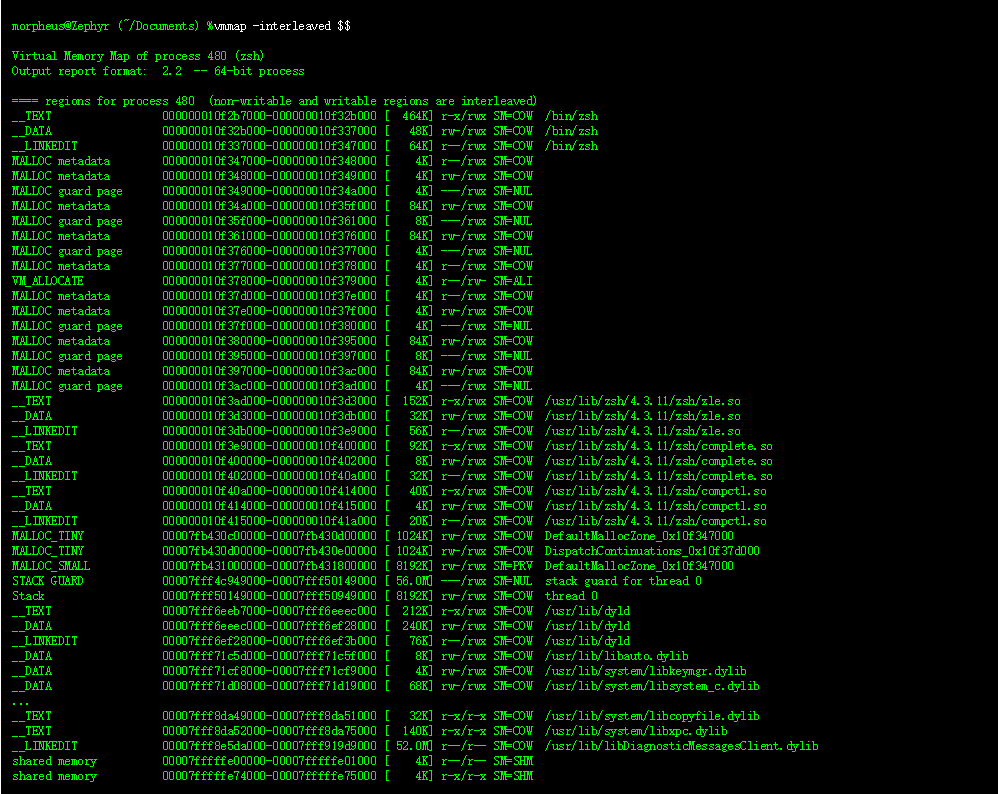
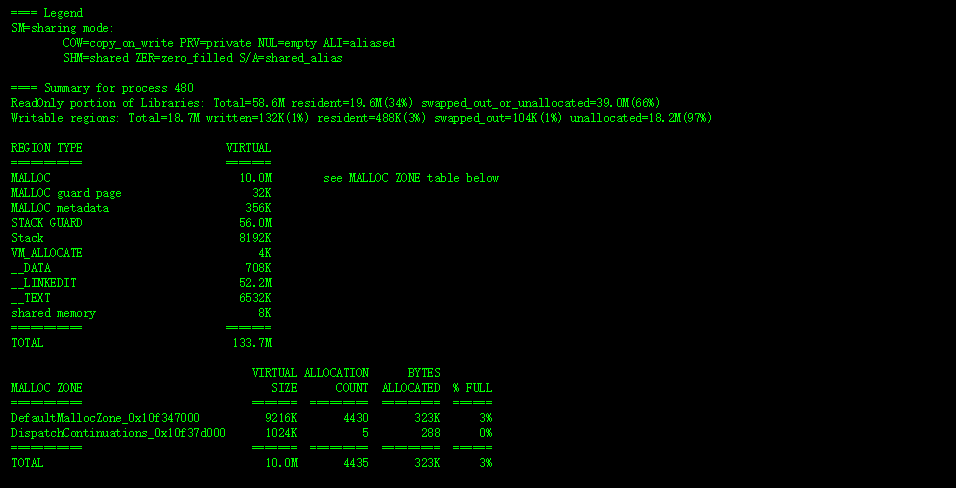
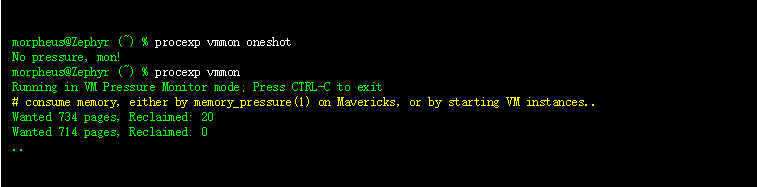
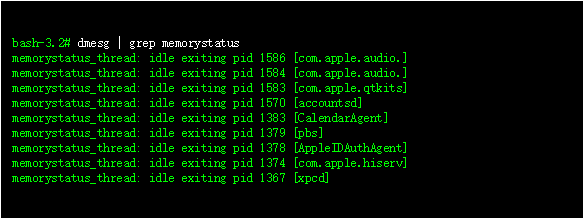
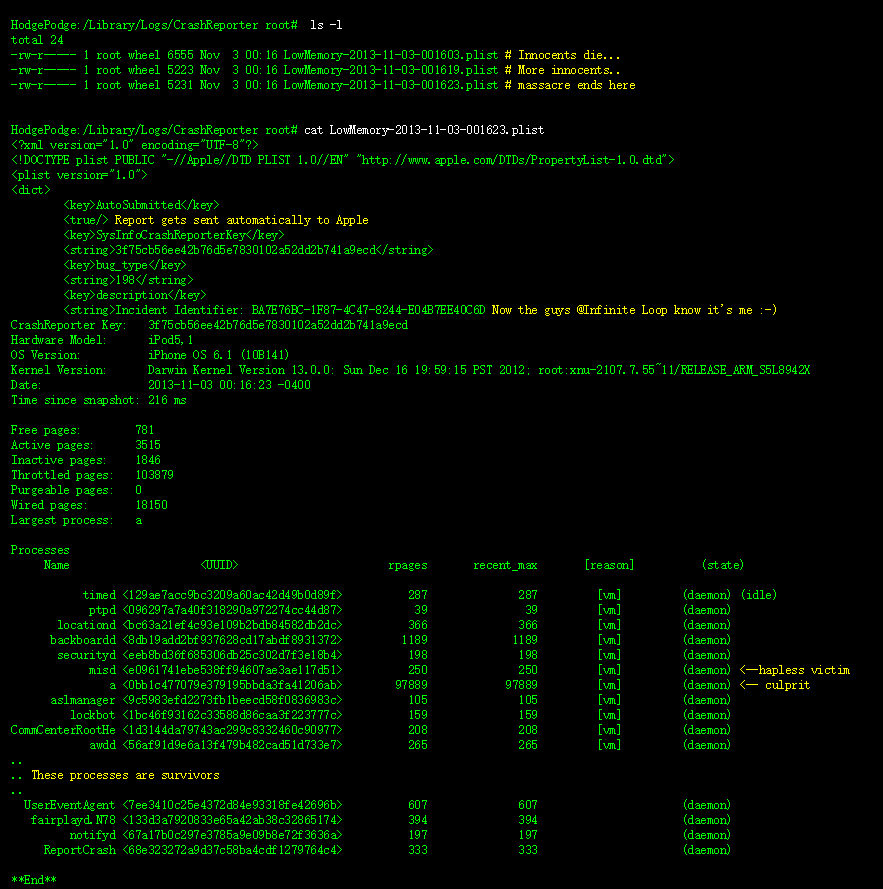
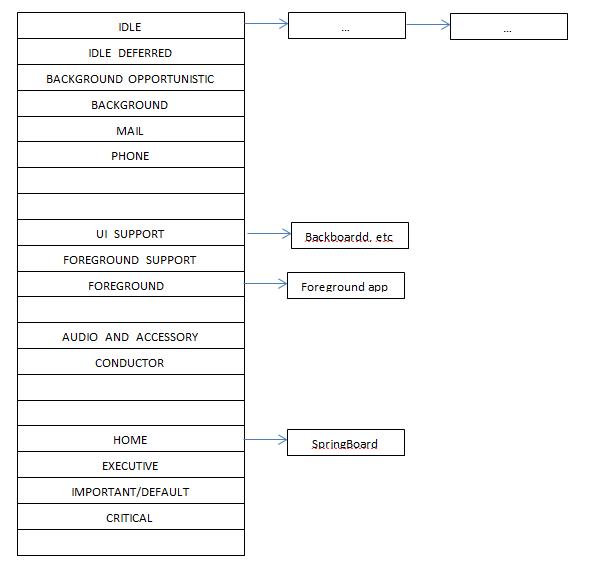
OS X 和 iOS 中的内存压力是虚拟内存管理的一个非常重要的方面,在我的书中[1]已经有了一些介绍。 我提到的 Jetsam/memorystatus 机制,已经随着时间的推移发生了重大变化,最终形成了最近在 Mavericks 中引入的一些非常重要的系统机制和系统调用。 在使用我的 OS X 和 iOS 的Process Explorer 时,我遇到了这些新增加的问题,因此在这里记录。 这是作为本书第12章的补充,当然也可以单独阅读。
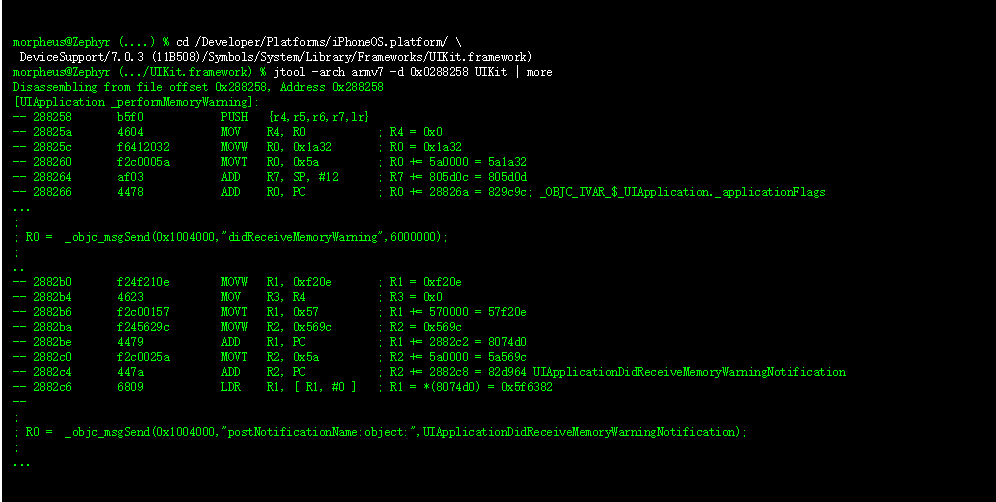
一般来说,注册了内存压力的应用程序(直接通过 Darwin API 或间接通过 UIKit)应该减少其缓存和潜在的不需要的内存(应该注意的是,遍历内存结构可能导致页面错误,会加剧内存压力)。 UIKit 是不开源的,但是当 UIApplication 遇到内存警告时,jtool 提供了一个很好的反汇编来演示它的行为:
3/1/2014 - Added jetsam properties plist from iPhone5s, and note about ledgers
2/10/2016 - Added jetsam/memorystatus commands for xnu 32xx (iOS 9, OS X 10.11). Also updated procexp to show mem limits on iOS
Footnotes
为了简单阐述,我们忽略了为某些给定进程提供的虚拟内存,实际上只是保留和映射以供内核使用的事实。顺便说一句,对于64位来说,是256TB,是由于硬件限制(加上没有人会真正使用它,更不用说是全64位的16EB)。 Mac OS X 以128-TB的47位(0x7fffffffffff)用做用户空间虚拟内存,最上面的(技术上为 0xffffffff8 …)128TB 为内核保留。
最后一点需要注意的地方就是:我们只将着重讲述 OS X 内核。这是由于在 iOS 上采取的安全措施,使得在 iOS 的环境中来利用这两个漏洞实在是要困难得多。另外,这篇博文也针对初学者,我们将尽量使讲述直接明了。
以下是本文的结构:
介绍(Introduction)
OSUnserializeBinary 概览 —— OSUnserializeBinary 的细节、数据格式以及具体如何运行。 (Overview of OSUnserializeBinary)
漏洞分析 —— 两个漏洞的具体分析 (Bugs analysis)
利用程序 —— 非常有趣的部分! (Exploitation)
总结(Conclusion)
OSUnserializeBinary 概览
XNU 内核实现了自己的一套规则,叫做 OSUnserializeXML,是用来对被存入内核的 XML 格式的数据进行反序列化。 最近,OSUnserializeBinary 作为新的函数加入了它。这个函数的用途跟 XML 是差不多的,但是处理的格式并不相同。OSUnserializeBinary 将二进制格式转换为基本内核数据对象。这种二进制格式虽然没有文档描述,但是非常简单。在分析函数的代码之前,我们先讲解一下这种格式。
<dict> <!-- new level (1) --> <string>str_3</string> <boolean>1</boolean>
<string>str_4</string> <boolean>1</boolean>
<string>str_5</string> <boolean>1</boolean> <!-- END LEVEL 1! --> <dict> <!-- there are objects after thisnew container --> <!-- we have to go back a level and push str_6 inside the outer dict --> <string>str_6</string> <boolean>1</boolean> <!-- END LEVEL 0! --> </dict>
<dict> <!-- END LEVEL 0! --> <string>str_3</string> <boolean>1</boolean>
<string>str_4</string> <boolean>1</boolean>
<string>str_5</string> <boolean>1</boolean> <!-- END LEVEL 1! --> <dict> <!-- there is nothing after this dict, donot indent and finally exit --> </dict>
WRITE_IN(dict, (0x000000d3)); // signature, always at the beginning WRITE_IN(dict, (kOSSerializeEndCollection | kOSSerializeDictionary | 2)); // dictionary with two entries WRITE_IN(dict, (kOSSerializeSymbol | 4)); // key with symbol, 3 chars + NUL byte WRITE_IN(dict, (0x00414141)); // 'AAA' key + NUL byte in little-endian WRITE_IN(dict, (kOSSerializeEndCollection | kOSSerializeNumber | 0x200)); // value with big-size number WRITE_IN(dict, (0x41414141)); WRITE_IN(dict, (0x41414141)); // at least 8 bytes for our big number
0x4141414141414141 // our valid number 0xffffff8033c66284 // 0xffffff8035b5d800 // 0x4 // other data on the stack between our valid number and the ret addr... 0xffffff803506d5a0 // 0xffffff8033c662b4 // 0xffffff818d2b3e30 // 0xffffff80037934bf // function return address ...
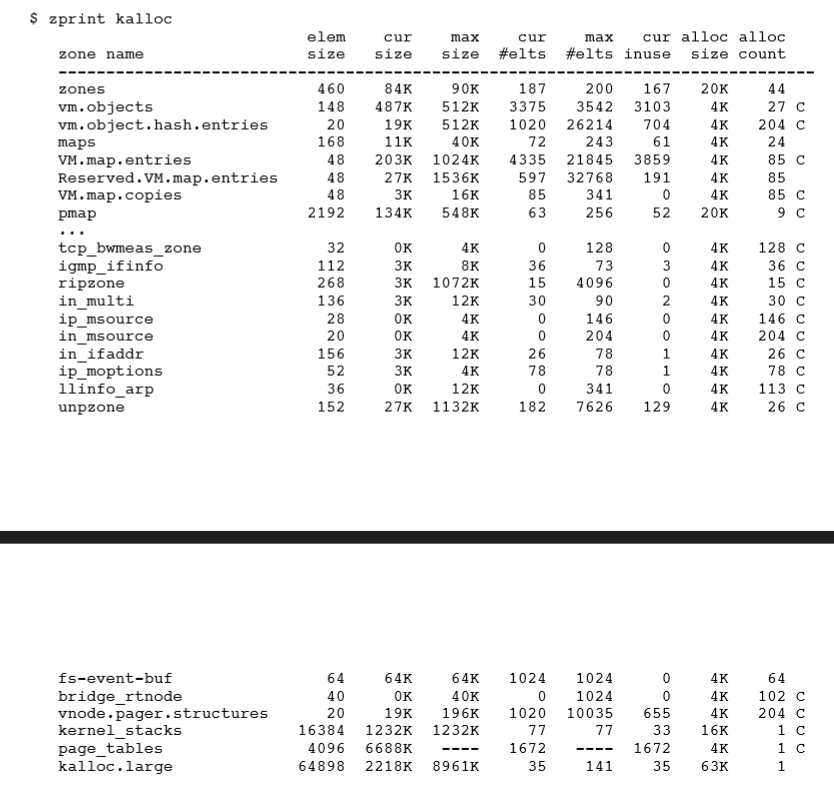
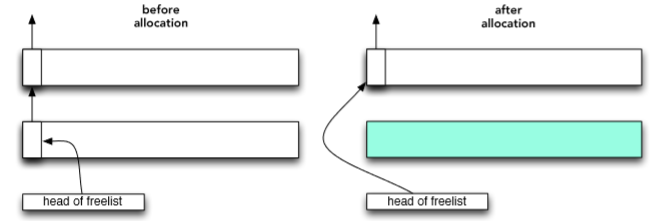
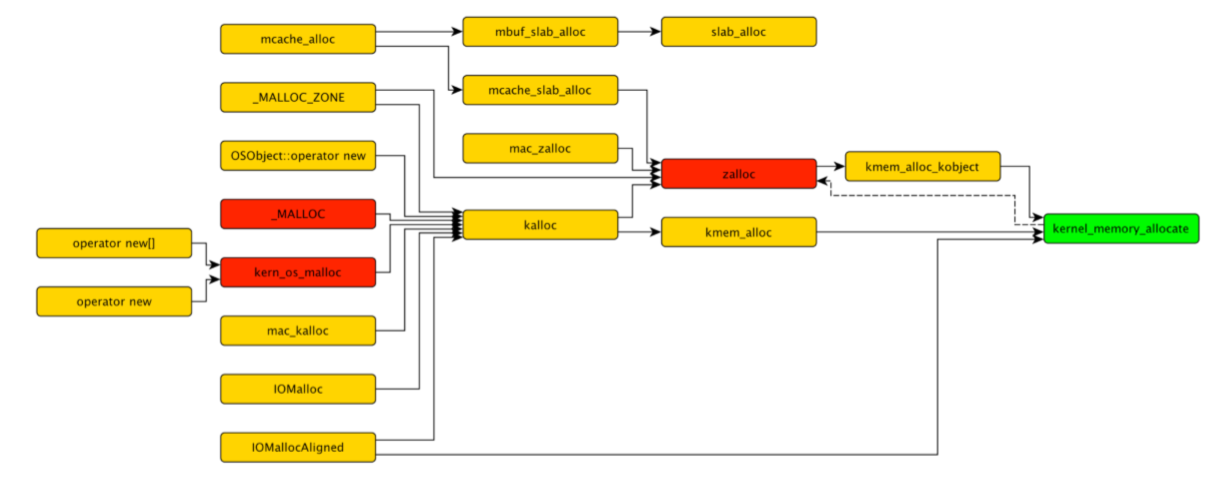
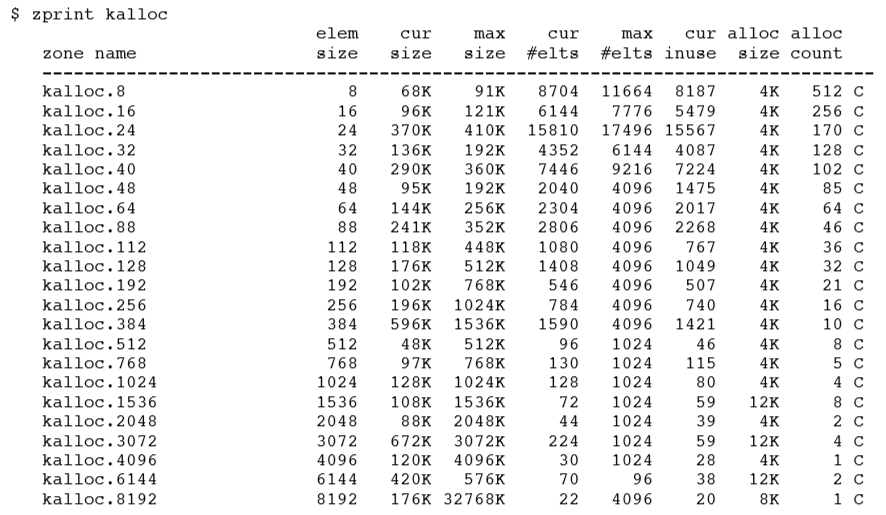
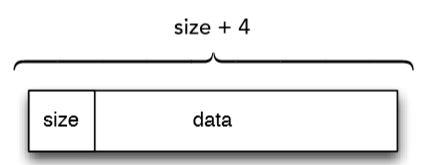
简单地讲,zalloc 在 zones 中组织分配,一个 zone 表示大小相同的分配列表。 最常用的区域是 kalloc 区域。 kalloc 是一个建立在 zalloc 之上的,更高级别的内核分配器。它将请求到的分配大小向上舍入到最接近的二的幂值。因此,注册的 kalloc 区域持有两个分配的权利。在 OS X 上使用 zprint 命令查看输出:









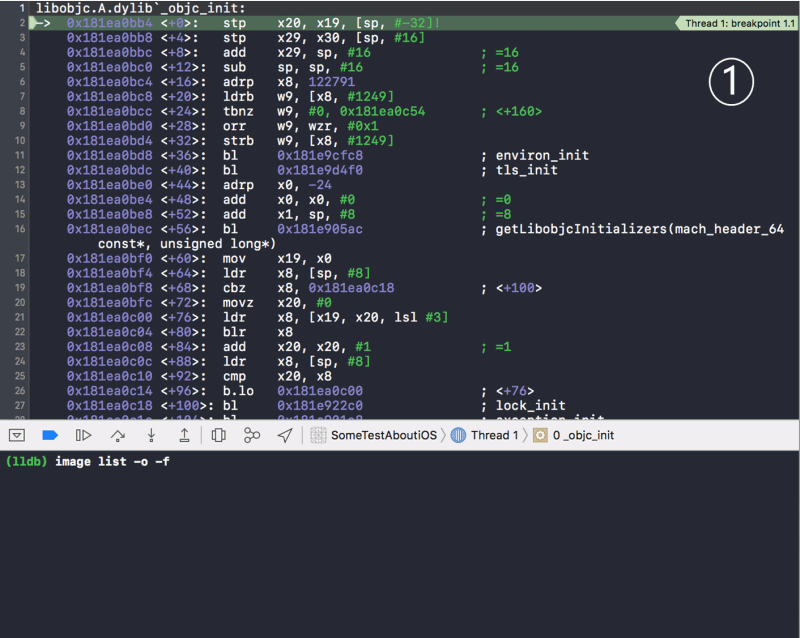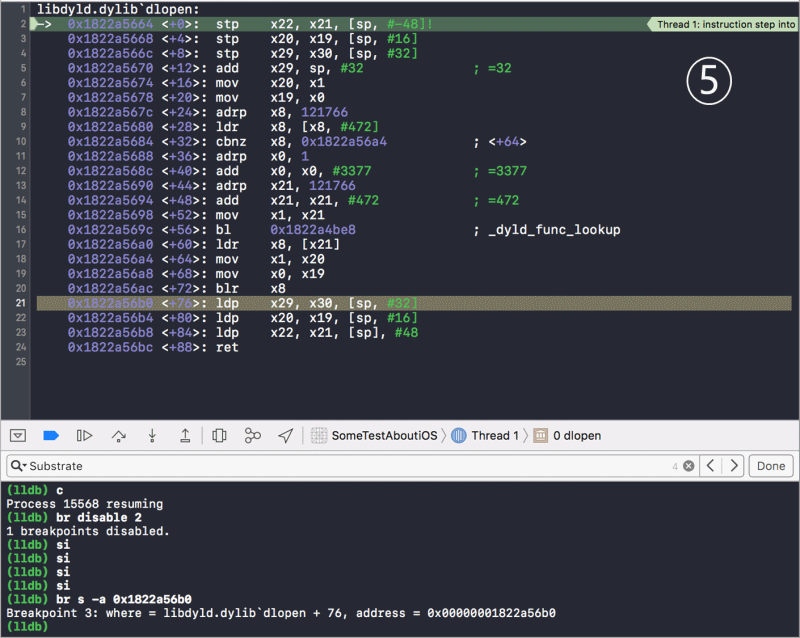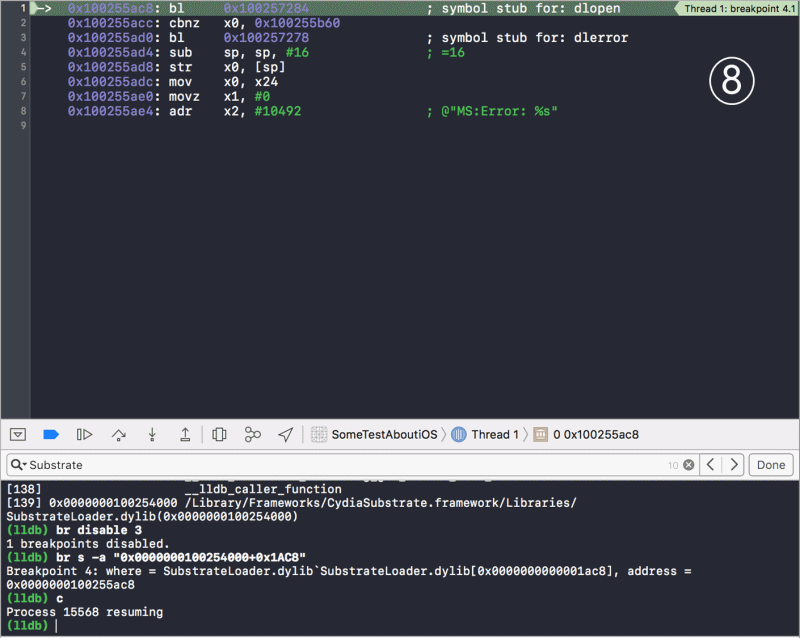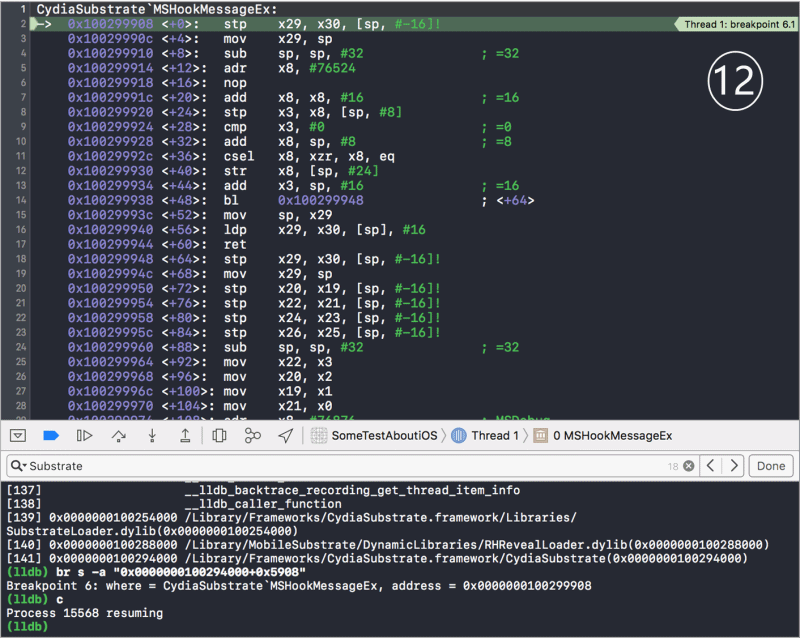

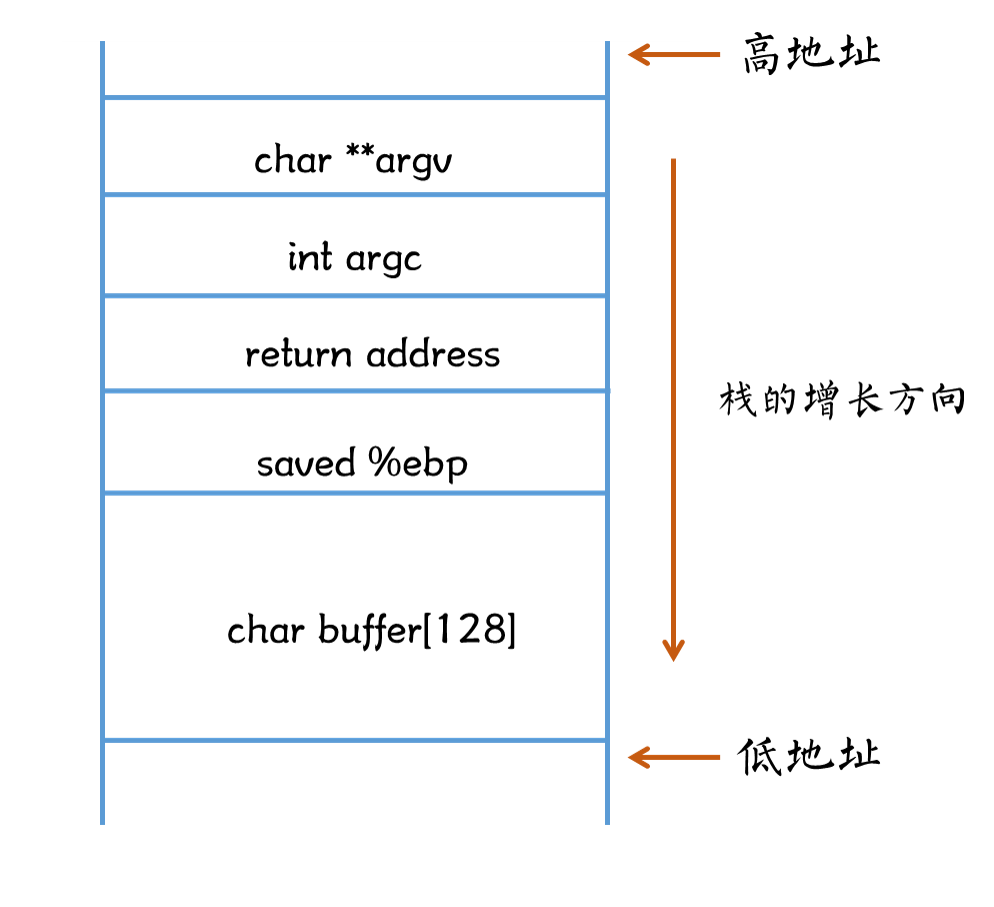
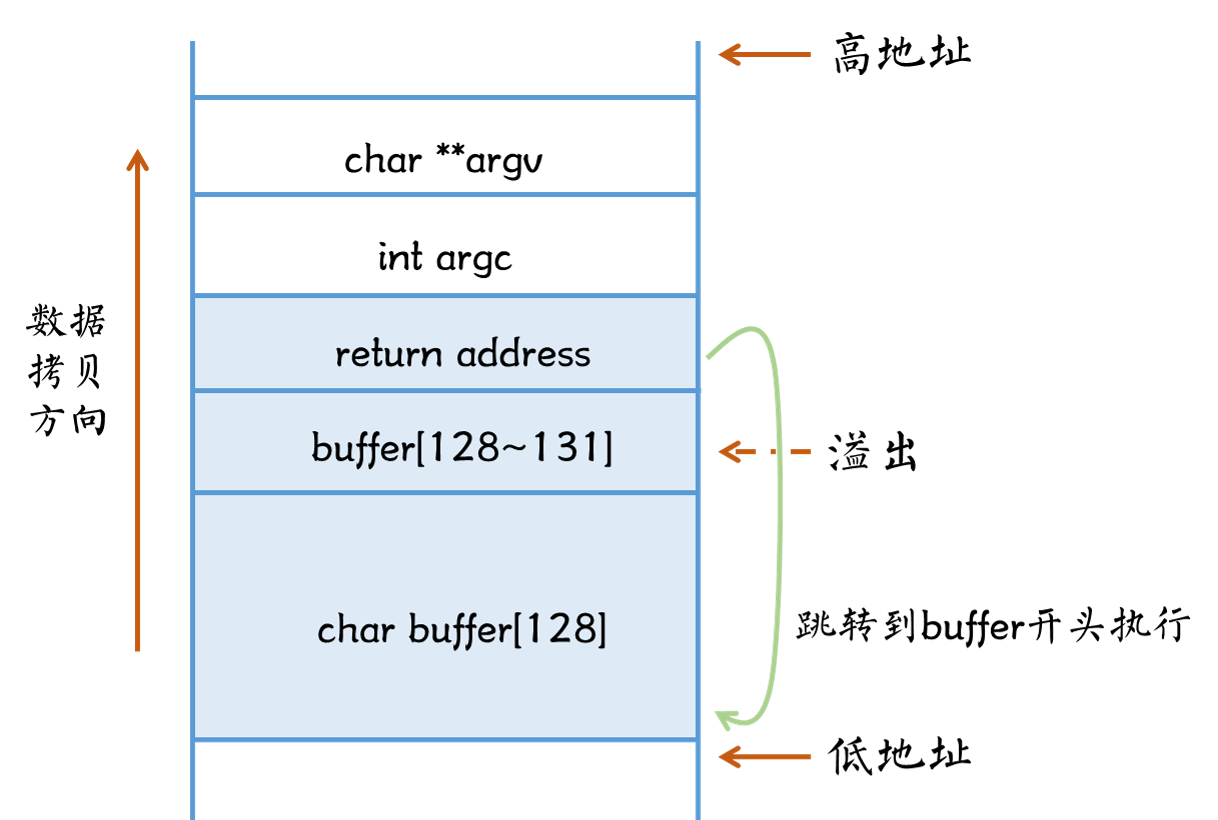
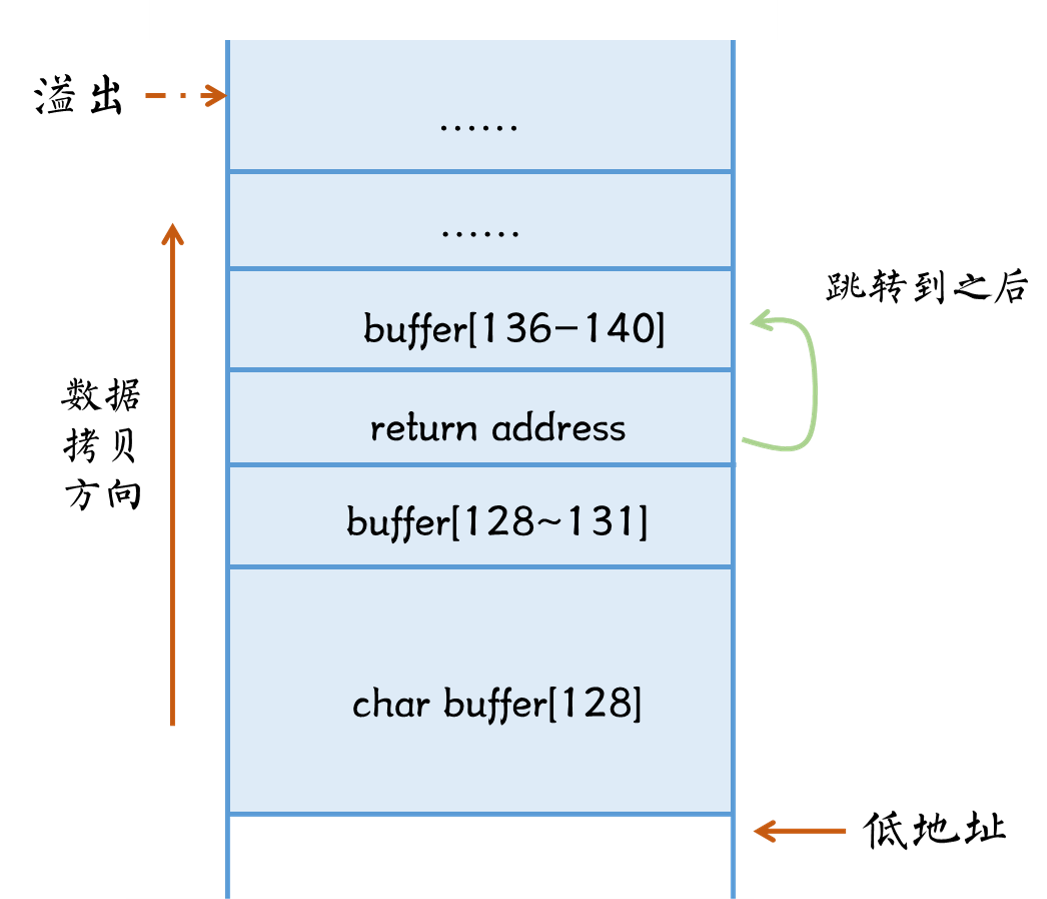
/图1.png)
/图2.png)